Git 的概念是什麼?這是一個非常重要的基礎知識,因為 Git 與一般原始碼控制的設計概念不同,知道 Git 運作概念,將會減少許多使用上的問題(減沙誤用而掉程式碼)。如果你要使用 Git,請先將過去所學的 VCS(版本控制系統)通通忘掉,例如 Subversion、SourceSafe、TFS…這樣做將有助於你學會 Git 這套 VCS,減少混亂的狀況。Git 在資料處理上的想法非常不同於其他 VCS 系統,有些使用方式類似,但是他背後的概念是非常不同的。了解這些不同處,將防止各種錯混淆並正確的使用 Git。
- 快照而不是差異 (Snapshots,Not Differences)
第一個最大的差異就是資料儲存概念上非常不同於其他 VCS系統。概念上,大多 VCS 是儲存一個以檔案為基礎的清單,這個清單在每次使用者確認變更(Commit)時會產生一份。但是只記錄差異,如圖:
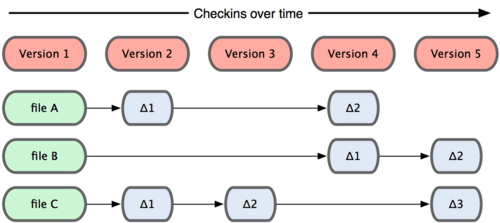
其他 VCS 是從一個 Base Version 開始儲存每次變更的差異檔案
Git 並不使用這種方式儲存資料,Git 的做法像是一個小型的資料快照系統。每次你進行 Commit 或是儲存狀態到你的 Git 專案時,,他是先將那一刻的所有資料進行一次的快照,那一次所產生的 Version 就指向那次的快照。為了提高效率,如果該次 Commit 沒有任何變更, Git 並不會把檔案再儲存一次,而是把新 Version 指向前一個版本的資料。如圖:
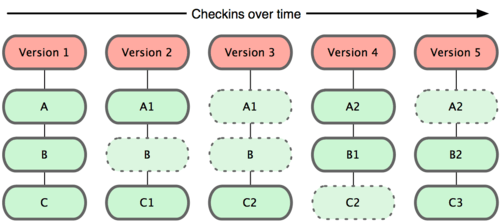
Git 每次都儲存專案的全部檔案快照
這是 Git 與其他 VCS 的重要差別,這讓 Git 設計者重新思考了版本控制系統,讓 Git 改成了更像一個小型檔案系統,並且可以在上面開發難以想像的強大功具,而不是只是一個簡單的 VCS 系統。你現在就可以想像他可以給你帶來什麼好處,後面將有討論。
- 幾乎所有動作都在本機進行(Every Operation Is Local)
大部份 Git 功能都只需要本機資源就可執行,一般來說不需要連到其他電腦取得資料才能運作,例如連到 Server 才能 Commit Version。如果你常因為網路 Lag 而感覺開發受阻,那使用 Git 會讓你感覺到有如神助般的神速,因為你有整個原始碼歷程在你的本機磁碟上,大多的操作都是瞬間完成。
例如你想要看某個專案的歷程,Git 不需要連到 Server 取得歷程資料才能顯示,Git 是直接讀取本機硬碟中的資料庫,意思是你可以瞬間就看到這個專案的歷程。如果你想看一個月前的版本與目前版的差異,Git 可以直接在本機進行計算,而不需要從一個遠端的 Server 上下載舊版資料進行計算。
如果你想在飛機上、火車上做一些工作,你可以儘情工作,做你想做的,然後再到有網路的地方進每上傳。如果你在家裡無法使用 VPN 時,你仍然可以工作。在許多其他 VCS 系統上做這些事情是不可能的,你要作的許多事情都需要連到 Server。雖然你可以編輯檔案,但是無法 Commit 檔案。這也許看起來不是什麼大功能,但是你使用後會覺得這是一個非常大的差別。
Git 的完整性(Git Has Integrity)
Everything in Git is check-summed before it is stored and is then referred to by that checksum. This means it’s impossible to change the contents of any file or directory without Git knowing about it. This functionality is built into Git at the lowest levels and is integral to its philosophy. You can’t lose information in transit or get file corruption without Git being able to detect it.
The mechanism that Git uses for this checksumming is called a SHA-1 hash. This is a 40-character string composed of hexadecimal characters (0–9 and a–f) and calculated based on the contents of a file or directory structure in Git. A SHA-1 hash looks something like this:
24b9da6552252987aa493b52f8696cd6d3b00373
You will see these hash values all over the place in Git because it uses them so much. In fact, Git stores everything not by file name but in the Git database addressable by the hash value of its contents.
Git Generally Only Adds Data
When you do actions in Git, nearly all of them only add data to the Git database. It is very difficult to get the system to do anything that is not undoable or to make it erase data in any way. As in any VCS, you can lose or mess up changes you haven’t committed yet; but after you commit a snapshot into Git, it is very difficult to lose, especially if you regularly push your database to another repository.
This makes using Git a joy because we know we can experiment without the danger of severely screwing things up. For a more in-depth look at how Git stores its data and how you can recover data that seems lost, see Chapter 9.
The Three States
Now, pay attention. This is the main thing to remember about Git if you want the rest of your learning process to go smoothly. Git has three main states that your files can reside in: committed, modified, and staged. Committed means that the data is safely stored in your local database. Modified means that you have changed the file but have not committed it to your database yet. Staged means that you have marked a modified file in its current version to go into your next commit snapshot.
This leads us to the three main sections of a Git project: the Git directory, the working directory, and the staging area.
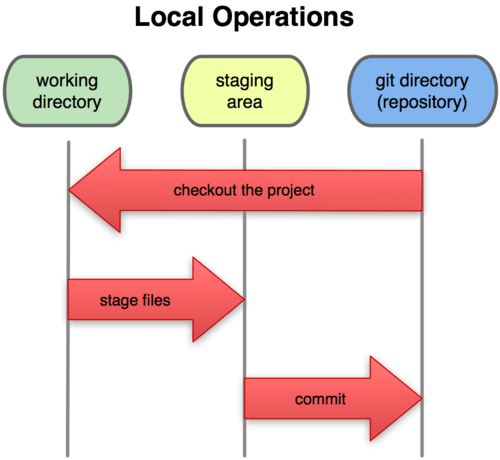
Figure 1-6. Working directory, staging area, and git directory.
The Git directory is where Git stores the metadata and object database for your project. This is the most important part of Git, and it is what is copied when you clone a repository from another computer.
The working directory is a single checkout of one version of the project. These files are pulled out of the compressed database in the Git directory and placed on disk for you to use or modify.
The staging area is a simple file, generally contained in your Git directory, that stores information about what will go into your next commit. It’s sometimes referred to as the index, but it’s becoming standard to refer to it as the staging area.
The basic Git workflow goes something like this:
You modify files in your working directory.
You stage the files, adding snapshots of them to your staging area.
You do a commit, which takes the files as they are in the staging area and stores that snapshot permanently to your Git directory.
If a particular version of a file is in the git directory, it’s considered committed. If it’s modified but has been added to the staging area, it is staged. And if it was changed since it was checked out but has not been staged, it is modified. In Chapter 2, you’ll learn more about these states and how you can either take advantage of them or skip the staged part entirely.
沒有留言:
張貼留言